RST: Residual Side Tuning with Cross-Layer Correlation for Parameter Efficient Transfer Learning
Abstract
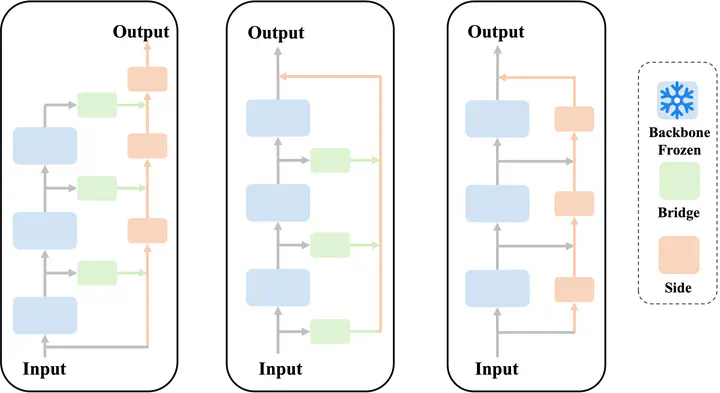
Existing fine-tuning methods for pre-trained models, including parameter-efficient transfer learning (PETL) approaches, suffer from inefficient information extraction and substantial resource consumption. To address these issues, we present Residual Side Tuning (RST), a novel PETL framework designed to enhance information extraction efficiency while maintaining minimal additional parameters. Specifically, RST extracts aggregated features, i.e., residuals, and employs a dual-block side tuning structure–Collect Blocks extract inter-layer information into residuals while Feed Blocks strategically reintegrate them back into the backbone. This parallel processing framework effectively models cross-layer relationships and significantly improves the efficiency of hierarchical feature extraction. Furthermore, RST reinforces these relationships by leveraging an element-wise feature enhancement strategy that integrates residuals with the current layer’s outputs, thereby augmenting information extraction capabilities. This enhanced extraction efficiency enables a parameter sharing strategy within the Collect Blocks, significantly reducing the number of trainable parameters through shared adaptations across multiple layers. Extensive experiments on several benchmark datasets, particularly in low-shot learning scenarios, demonstrate that RST not only outperforms existing PETL methods in accuracy but also achieves substantial reductions in both parameter and memory usage.
Yue Xin
忻岳 | Second-Year Master’s Student
My research interests include machine learning, large (language) models, and interpretable AI. Welcome to contact me !