GLEAM: Global Share Local Transform MoE for Downstream Transferring With Enhanced Parameter Efficiency
Abstract
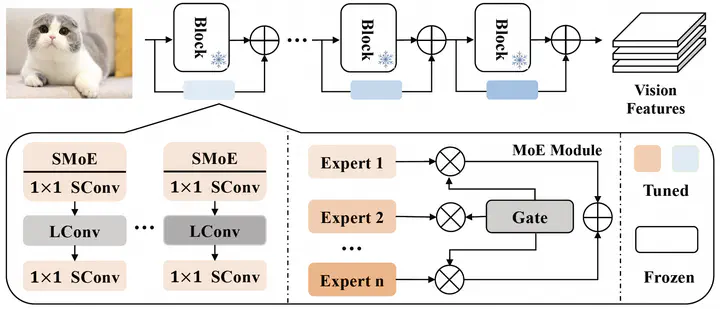
Parameter-efficient transfer learning (PETL) has emerged as a promising direction to fine-tune lightweight modules and adapt large-scale pre-trained models to downstream tasks. Nevertheless, these methods have not thoroughly explored the characteristics of PETL methods to optimize the fine-tuning performance with miminal volume of parameters. In this paper, we first reveal that, compared to pre-trained models, PETL tends to generate similar features via homogeneous feature transformations across different layers. Subsequently, we propose a Global Sharing Local Transformation framework, namely Gleam that decomposes the adapter into a shared component and layer-specific local components to simultaneously reduce the redundancy in layer-wise parameter matrices for homogeneous feature transformations and fine-tune the locally specific parameters for minimizing performance loss. Speficially, we develop a shared mixture of convolution that introduces shared multi-scale sparse MoE to enable diverse transformations for suppressing the homogeneity issue of feature transformations in PETL. To accurately evaluate Gleam, we test it on more than 20 datasets for image classification and few-shot learning performance. Experimental results demonstrate that the proposed method performs on par with existing PETL methods like LoRA with only 3% of its parameters and further yields competitive performance using only 0.07M parameters.
Yue Xin
忻岳 | Second-Year Master’s Student
My research interests include machine learning, large (language) models, and interpretable AI. Welcome to contact me !